条件付き独立と有向分離を用いた統計モデルの妥当性チェック
この記事では条件付き独立と有向分離を使い、作成したモデルが背景知識と齟齬がないかチェックする方法を紹介します。以下の本の4章と5.3.1項を参考にしています。
Modeling and Reasoning with Bayesian Networks
僕が持っているのは上の一版なのですが、新しい二版が出ているみたいです。

Modeling and Reasoning with Bayesian Networks
- 作者:Darwiche, Adnan
- 発売日: 2014/08/07
- メディア: ペーパーバック
条件付き独立とは
以降では確率変数の集合を太文字でのように太文字で表します。確率変数が1つの場合は
のように表します。
条件付き独立とは「の値が与えられると、
は
と独立になる」ことを指します。
で表現します。「
が与えられると、
の情報は
を推測する上でヒントにならない。」と表現することもできます。
「確率変数と
が独立」とは
を意味するのでした。条件付き独立は以下を意味します。
両辺をで割ることで、以下の形で表現することもできます(
とします)。
あるグラフィカルモデルが与えられると、たちどころに各ノード
について
が成り立ちます。ここで
は
の親で、
へ直接矢印が向いているノードの集合です。
は
の子孫、すなわち
から矢印の向きに沿ってたどりつけるノードの集合です。したがって
は子孫以外の集合です(ただし
は除く)。
それでは上記以外の条件付き独立はグラフィカルモデルに含まれていないのでしょうか。いいえ、次に挙げる性質で他の条件付き独立を導くことができます。
条件付き独立の諸性質
ここでは4つだけ取り上げます。
| 性質の名前 | 式 | 解釈 |
|---|---|---|
| 対称 symmetry |
||
| 分解 decomposition |
||
| 弱結合 weak union |
||
| 縮約 contraction |
関連のない |
備考
- 合成(composition)
以下の「合成(composition)」は一般に成り立たない。縮約(contraction)との違いに注目。
かつ
ならば
- 分解(decomposition)から導かれること
をあるグラフ
のノードとすると、すべての
に対し、
が成り立つ。
- 弱結合(weak union)から導かれること
をあるグラフ
のノードとすると、任意の
に対し、
が成り立つ。
証明
各性質の証明です。興味なければ飛ばしてください。本に載っていなかったので僕が足したものです。間違っていたらすみません。
- 対称(symmetry)の証明
- 分解(decomposition)の証明
2つめの等号で仮定を使っています。
- 弱結合(weak union)の証明
2つめの等号で仮定を使っています。また、仮定に分解(decomposition)を適用すると、すなわち
が成り立つので、それを最後の等号で使っています。
- 縮約(contraction)の証明
2つめの等号で2番目の仮定を使っています。最後の等号で1番目の仮定を使っています。
有向分離とは
グラフィカルモデルが大きくなると、あるノードの集まりと
の条件付き独立を調べるのは大変になります。もっと簡単かつ効率的に条件付き独立を判定するにはどうすればいいでしょうか。解決策の一つが有向分離(d-separation)です。
交わりを持たないがあって、あるグラフ
において
と
が
によって有向分離(d-separated)されているとは、
と
をつなぐすべてのパス(矢印の向きは無視してよい)が
によってブロックされていることを指します。
と表記します。
ブロックの前に「バルブが閉まっている」の説明をします。以下の3つの場合にと
が独立になり、
と
の間のバルブが閉まっていると言います。
というパスの形において、
が与えられている場合
というパスの形において、
というパスの形において、
「ブロックされている」とはパスのどこかで、少なくとも1つのバルブが閉まっていることです。この定義によると、バルブがそもそもない場合(すなわち直接矢印でとなっている場合)にはブロックされようがありません。
この部分の説明と証明はPRML下の8.2節が分かりやすいです。
")
- 作者:C.M. ビショップ
- 発売日: 2012/02/29
- メディア: 単行本
に含まれない葉ノード(矢印が出ていないノード)を取り除く。葉ノードへ入る矢印も除く。グラフが変わらなくなるまでこのステップを繰り返し適用する。
から出ている矢印を取り除く。
と
をつなぐパス(矢印の向きは無視してよい)が存在しなければ
。
そして有向分離と条件付き独立は以下の定理で結びつきます。
なお、無向グラフではというパスの形において、
が与えられている場合がブロックとなります。つながっているかどうかだけ見ればよいので簡単です。
有向分離の練習
本のFig4.12から引用です。以下のDAGを考えます。

- 例1
上のDAGにおいて、と
が
によって有向分離されているか考えます。
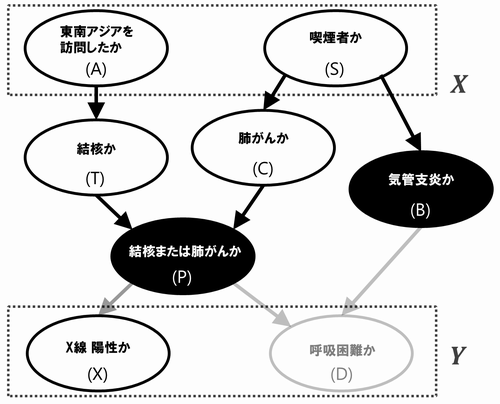
データが与えられた確率変数は黒丸に白文字で書くのが慣例なのでそうしています。それでは実際に手順を適用してみましょう。判定方法の手順1によりを取り除きます。手順2により
の矢印を除きます。すると、
と
をつなぐパスはありませんので
と判定できます。
- 例2
上のDAGにおいて、と
が
によって有向分離されているか考えます。
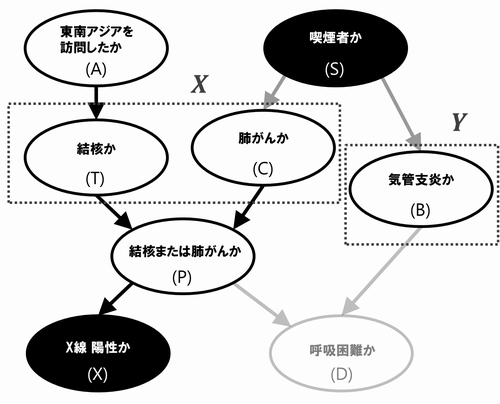
同様に判定方法の手順1によりを取り除きます。手順2により
と
の矢印を除きます。すると、
と
をつなぐパスはありませんので
と判定できます。
作成したモデルが背景知識と齟齬がないかチェックする例
本のFig5.9からの引用です。病気の診断をするモデルを2つ考えます。
1つめは以下のようなDAGです。モデル1としましょう。

2つめは以下のようなDAGです。モデル2としましょう。
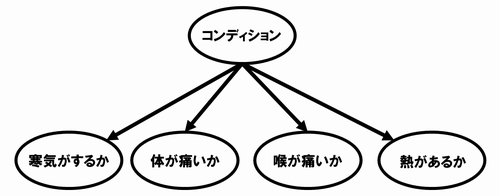
モデル1がよいのかモデル2がよいのか考えています。いろいろな判断基準があると思いますが、ここでは背景知識とも言える「条件付き独立」と照らし合わせて考えてみます。
- 「風邪を引いている」と分かっているとします。モデル1では「熱があるか」と「喉が痛いか」は有向分離になりません。「熱があるか」分かれば(恐らく扁桃炎の可能性がアップして)「喉が痛いか」かどうかのヒントになり得ます。一方、モデル2では「コンディション」が分かっているとすると、「熱があるか」と「喉が痛いか」は有向分離となり、条件付き独立になります。
- モデル1では何もわかっていない状態においても、「体が痛い」と「扁桃炎」、「体が痛い」と「風邪」はそれぞれ有向分離となっており、条件付き独立となります。従って「体が痛い」という情報は「扁桃炎か」どうか「風邪か」どうかのヒントになりません。モデル2では有向分離していないので、「体が痛い」という情報は(インフルエンザの可能性を高め)「扁桃炎」および「風邪」があるかどうかのヒントになり得ます(恐らくこれらの可能性を減らすでしょう)。
- モデル1では何もわかっていない状態においても、「熱があるか」と「風邪か」は有向分離となっており、条件付き独立となります。従って「熱がない」という情報は「風邪か」どうかのヒントになりません。モデル2では有向分離していないので、「熱がない」という情報は恐らく「風邪である」可能性を高めるでしょう。
このように条件付き独立と有向分離の考え方は背景知識と照らし合わせて統計モデリングに活用することができます。
その他の参考文献
グラフィカルモデルには上記以外にも無向グラフ、I-MAP、Perfect MAP、ネットワーク構造推定などさまざまなトピックがあります。詳しく知りたい読者は上記で挙げた二冊の本を参照してください。
因果推論の身近な話やバックドア基準については上記で挙げた本には載ってませんので、岩波DS3を読むとよいと思います。他の話も分かりやすく、実験者や研究者にオススメです。

- 発売日: 2016/06/10
- メディア: 単行本(ソフトカバー)