データ解析で割安mobile PCを探す
この記事の続編です。一緒にやろうという人がなかなか現れないので、一人でたたき台を作りました。
目的
目的は機能の割にお得な割安mobile PCを探すことです。mobile PCの厳密な定義はないのですが、ここではディスプレイが12型~14型で重さが1kg前後としました。また、各社の最新モデルだけを対象としました。
データの取得方法
メーカーを決める→本気で買うつもりで公式サイトと価格comを比較して安い方にする→人力スクレイピング です。現時点では公式サイトも多く、スクレイピングのコードを書いても労力のもとが取れないので10時間ほどかけて人力スクレイピングして集めました。
データの内容
8社・10モデルで44商品です。おすすめモデルを中心にしました。生データを置いておきます(これとこれ)。
次の統計モデリングで使用する、PCの機能を表す説明変数は18個考慮しました。CPU・メモリ・SSD・PCIe・ディスプレイのサイズ/解像度/光沢非光沢・重さ・バッテリ持続時間・キーボードバックライト・LANポート・SIMポート・USB3.0の数・USB3.1の数・各種出力などです。前処理はそこそこ必要で、例えばCPUはこのサイトのベンチマークスコアの値に変換して使いました。また、キーボードの打ちやすさ、画面の見やすさ、公称でないバッテリー持続時間などはこちらのサイトから取得して、一部を説明変数として使いました。目的変数は税込み価格です。
簡単な可視化は記事の最後にある発表資料を見てください。
統計モデル
切片・説明変数の項・ブランド(会社名の影響)の項からなるシンプルな回帰です。ブランドは正規分布に従うとし、その標準偏差は弱情報事前分布を設定し、データから推定しました(階層モデル)。例えば「Think Padのキーボードが打ちやすい」という特徴があっても、今回は会社の影響と切り分けできないのでブランドの影響に組み込まれることになります。
計算方法
StanとRで計算しました。記事の最後の方にコードを載せておきます。計算時間はSurface Pro 3で1chainあたり約20秒ほどです。
結果
説明変数の影響
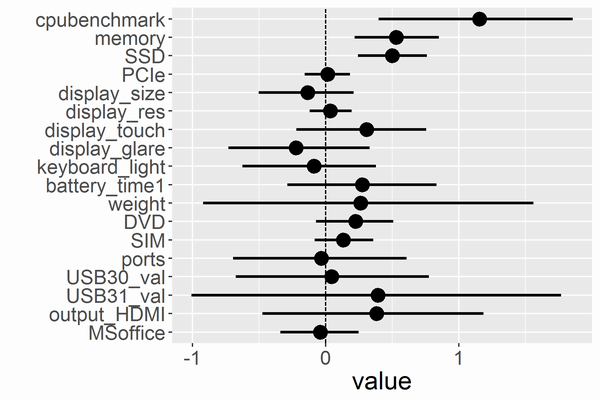
黒い点が推定した事後分布(からのMCMCサンプル)の中央値で、横に伸びている線が95%ベイズ信頼区間です。
影響があると断言できそうなのは、CPUとメモリ容量とSSD容量ぐらいでした。重さは軽い方が高い傾向はあるのですが、95%区間がゼロをまたいでおり、そうも断言できない結果となりました。
ブランドの影響
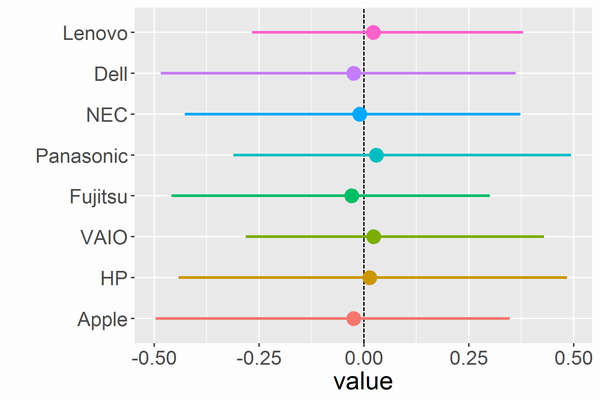
凡例は「説明変数の影響」と同じです。大差なしという結果です。あると思っていたのでやや残念です。
実際の価格 vs. 「潜在的な価値」
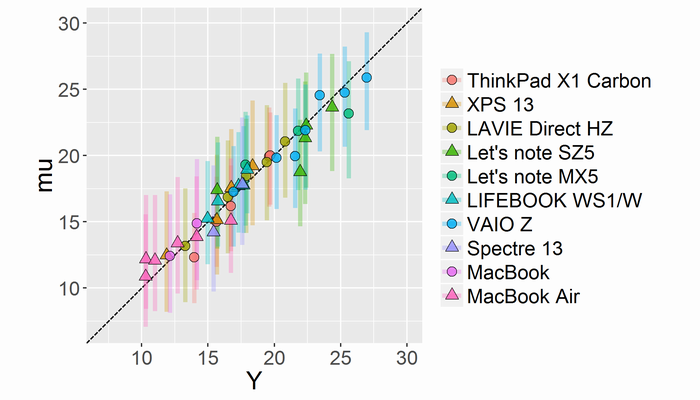
凡例は「説明変数の影響」と同じです。直線y=xの上側が割安な商品、直線y=xの下側が割高な商品です。ほとんどの商品が直線y=xの近くにあるので、目立つ割安・割高な商品はないと言えます。市場原理はなかなか強力のようです。どれも値段相応の価値があると言えるので、好きなもん買えばいいと思います。
しかしよく見ると、富士通の商品はMCMCサンプルの中央値がすべて割安側にあり、また(性能に関係ない)ブランド効果も比較的低いので、会社として見ると割安な商品を出す傾向にあると思います。たしかに公式サイトの訳あり商品はなんかいつも安い気がする。
割引%offのBest3・Worst3
目立った割安・割高な商品はないですが、例えばMCMCサンプルの中央値ベースで割引%offのBest3・Worst3なんかも求めることができます。
| best1 | best2 | best3 | worst1 | worst2 | worst3 | ||
|---|---|---|---|---|---|---|---|
| price | 103058 | 156800 | 109938 | 219427 | 139655 | 167184 | |
| 潜在的な価値 | 12.2万円 | 17.40万円 | 12.09万円 | 18.76万円 | 12.33万円 | 15.10万円 | |
| %off | 15.5 | 9.9 | 9.1 | -16.9 | -13.2 | -10.7 | |
| search_date | 20160717 | 20160717 | 20160717 | 20160717 | 20160717 | 20160717 | |
| search_site | kakaku | kakaku | kakaku | kakaku | official | official | |
| url | http://kakaku.com/item/K0000872152/ | http://kakaku.com/item/K0000855827/ | http://kakaku.com/item/K0000752290/ | http://kakaku.com/item/K0000855828/ | http://shopap.lenovo.com/jp/notebooks/thinkpad/x-series/x1-carbon/#tab-customize | http://www.apple.com/jp/shop/buy-mac/macbook-air | |
| company_name | Apple | Panasonic | Apple | Panasonic | Lenovo | Apple | |
| model_name | MacBookAir | Let'snoteSZ5 | MacBookAir | Let'snoteSZ5 | ThinkPadX1Carbon | MacBookAir | |
| CPU | Corei5-5250U | Corei5-6300U | Corei5-5250U | Corei5-6300U | Corei5-6200U | Corei7-5650U | |
| memory | 8 | 4 | 4 | 8 | 4 | 8 | |
| SSD | 128 | 128 | 256 | 256 | 128 | 256 | |
| PCIe | 1 | 0 | 1 | 0 | 0 | 1 | |
| display_size | 13.3 | 12.1 | 13.3 | 12.1 | 14 | 13.3 | |
| display_res_width | 1440 | 1920 | 1440 | 1920 | 1920 | 1440 | |
| display_res_height | 900 | 1200 | 900 | 1200 | 1080 | 900 | |
| display_touch | 0 | 0 | 0 | 0 | 0 | 0 | |
| display_glare | 1 | 0 | 1 | 0 | 0 | 1 | |
| display_vote | 0 | 0 | 0 | 0 | 1 | 0 | |
| keyboard_light | 1 | 0 | 1 | 0 | 1 | 1 | |
| keyboard_vote | 0 | 0 | 0 | 0 | 1 | 0 | |
| battery_size | 54 | NA | 54 | NA | 52 | 54 | |
| battery_time1 | 12 | 11.5 | 12 | 13 | 9.8 | 12 | |
| battery_time2 | NA | NA | NA | NA | 5.62 | NA | |
| weight | 1.35 | 0.875 | 1.35 | 0.849 | 1.18 | 1.35 | |
| DVD | 0 | 0 | 0 | 0 | 0 | 0 | |
| SIM | 0 | 1 | 0 | 0 | 0 | 0 | |
| LAN_port | 0 | 1 | 0 | 1 | 0 | 0 | |
| USB30 | 3 | 3 | 3 | 3 | 3 | 3 | |
| USB31 | 0 | 0 | 0 | 0 | 0 | 0 | |
| output_HDMI | 1 | 1 | 1 | 1 | 1 | 1 | |
| output_VGA | 0 | 1 | 0 | 1 | 0 | 0 | |
| SDcard | 1 | 1 | 1 | 1 | 1 | 1 | |
| MSoffice | 0 | 0 | 0 | 0 | 0 | 0 |
best1とbest3はMac Book Airのローエンドな商品です。これらは少々古い割に人気があるので、取り扱っている店が多く、価格comで激しい競争にさらされてお買得になっていると思われます。一方で、Appleの公式サイトで選んだハイエンドな商品はworst3になっています。Appleの公式サイトで買うのは割高の傾向があると言えるでしょう。
best2とworst1はLet's note SZ5です。ともに価格comで扱っている店も十分にあるのにこの差があるところが面白いです。1商品にしぼって価格comを信じるのではなく、データ解析の関係者ならメタな視点でお買い得な商品を選びたいものです(まあ統計モデルもお買い得かも仮説にすぎないのですが)。
Future work
価格comのWeb APIやAmazon APIを使って、商品を最新モデルに限らず、さらに扱っている店舗の影響や価格推移などのデータを集めるのは考えられます。ただし、取り扱っている店の少なさ、限定モデルかどうか、などをチェックしてフィルターする必要がありそうです。しかし、データが増えれば、「ある会社の製品は早く値段が落ちる」なんてことも分かりそうな気がします。データを定期的に取得するのが面倒なんだよなぁ。
ソースコード
Stanコードは以下です。
data { int N; int D; int K; matrix[N,D] X; vector[N] Y; int N2K[N]; } parameters { vector[D] beta; vector[K] brand; real<lower=0> s_Y; real<lower=0> s_brand; } transformed parameters { vector[N] mu; vector[N] mu_plus_brand; mu = X*beta; mu_plus_brand = mu + brand[N2K]; } model { beta[1] ~ student_t(4, 0, 3); beta[2:(D-1)] ~ student_t(4, 0, 1); s_brand ~ student_t(4, 0, 1); brand ~ normal(0, s_brand); Y ~ normal(mu_plus_brand, s_Y); }
実行するRコードは以下です。
library(rstan) d <- read.csv(file='input/data.csv', stringsAsFactors=FALSE) d_cpu <- read.csv(file='input/cpu_info.csv', skip=1, stringsAsFactors=FALSE) rownames(d_cpu) <- d_cpu$CPU company_names <- c('Lenovo', 'Dell', 'NEC', 'Panasonic', 'Fujitsu', 'VAIO', 'HP', 'Apple') d$company_name <- factor(d$company_name, levels=company_names) d$cpubenchmark <- d_cpu[d$CPU, ]$cpubenchmark/4000 d$price <- d$price/100000 d$display_res <- (d$display_res_width * d$display_res_height)/1920/1080 d$battery_time1 <- d$battery_time1/20 d$memory <- d$memory/16 d$SSD <- d$SSD/512 d$ports <- d$LAN_port usb_cvt <- c('0'=0, '1'=0.5, '2'=0.8, '3'=1) d$USB30_val <- usb_cvt[as.character(d$USB30)] d$USB31_val <- usb_cvt[as.character(d$USB31)] Y <- d$price gr <- d$company_name use_cols <- c('cpubenchmark', 'memory', 'SSD', 'PCIe', 'display_size', 'display_res', 'display_touch', 'display_glare', 'keyboard_light', 'battery_time1', 'weight', 'DVD', 'SIM', 'ports', 'USB30_val', 'USB31_val', 'output_HDMI', 'MSoffice') X <- data.frame(1, d[ , use_cols]) data <- list(N=nrow(X), D=ncol(X), K=nlevels(gr), X=X, Y=Y, N2K=as.numeric(gr)) stanmodel <- stan_model(file='model/model.stan') fit <- sampling(stanmodel, data=data, seed=1)
発表資料
9/7にYahoo!でこの内容でLTしました。資料は以下です。